Table of contents
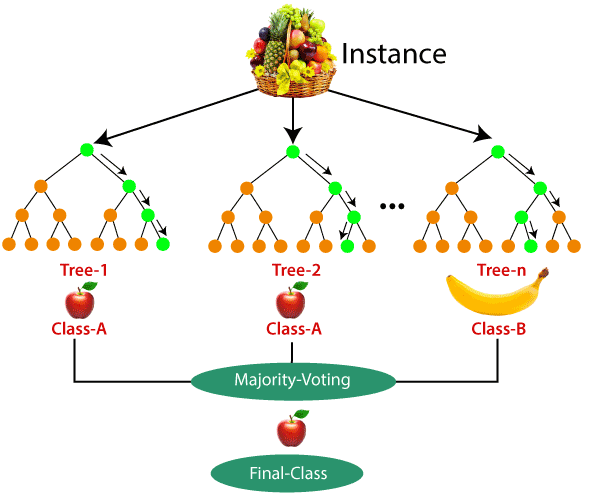
Random Forest is an ensemble learning algorithm that is used for both classification and regression tasks. It is a powerful machine learning technique that combines multiple decision trees to create a forest of trees and then outputs the class that is the mode of the classes of the individual trees.
What are Random Forests?
Random Forests were introduced by Leo Breiman and Adele Cutler in 2001. It is an extension of the decision tree algorithm, which is used to predict the class of a sample based on a set of features. The basic idea behind the Random Forest algorithm is to create multiple decision trees and combine them to make a more accurate prediction.
In a Random Forest, a set of decision trees are built on random subsets of the training data. The decision trees are built using a random selection of features at each split in the tree. The output of each tree is used to determine the final output of the Random Forest. The final output is calculated by taking the mode of the output of all the decision trees.
Advantages of Random Forests?
Random Forests have several advantages over decision trees. First, they are less prone to overfitting because they combine multiple decision trees. Second, they can handle missing values and noisy data because they use a subset of the features at each split in the tree. Third, they are computationally efficient and can be used for large datasets.
With the increasing availability of data and computing power, the use of Random Forests is becoming more common in various fields, such as finance, healthcare, and marketing. However, it is important to note that the quality of the results obtained by a Random Forest model depends on various factors, such as the quality of the data, the number of trees, and the tuning of hyperparameters.
Code Example
Here's an example code for Random Forest Classifier using Pytho:
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# generate a random dataset
X, y = make_classification(n_samples=1000, n_features=10,
n_informative=5, n_redundant=0, random_state=0, shuffle=False)
# split the dataset into training and testing data
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size=0.2, random_state=42)
# create a random forest classifier
clf = RandomForestClassifier(n_estimators=100, max_depth=2,
random_state=0)
# train the classifier on the training data
clf.fit(X_train, y_train)
# make predictions on the test data
y_pred = clf.predict(X_test)
# calculate the accuracy of the classifier
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)
In this code, we are generating a random dataset using the make_classification function from scikit-learn. We are then splitting the dataset into training and testing data, creating a Random Forest Classifier with 100 trees and a maximum depth of 2, training the classifier on the training data, making predictions on the test data, and calculating the accuracy of the classifier using the accuracy_score function from scikit-learn.
Conclusion
In conclusion, Random Forests is a powerful machine learning algorithm that offers numerous benefits to data scientists and businesses. By aggregating the predictions of multiple decision trees, Random Forests can provide more accurate predictions and reduce overfitting. Additionally, it can handle a wide range of data types, including categorical and continuous variables, making it a versatile option for many applications.